A unified platform for high-quality Synthetic Data: Unlocking the Power of Synthetic Data for Healthcare Innovation
The rapid digital transformation of healthcare relies on vast amounts of data to drive innovation in diagnostics, treatment, and patient care. However, stringent privacy regulations and data accessibility challenges limit the use of real-world patient information. Synthetic data—artificially generated datasets that maintain the statistical properties of real patient data—offers a transformative solution.
By enabling AI-driven medical research, synthetic data enhances decision-making, supports drug development, and facilitates the creation of next-generation healthcare technologies while preserving patient privacy. SYNTHIA is developing an evaluation framework for benchmarking synthetic data quality and ensuring regulatory compliance. The project integrates a federated data-sharing infrastructure to enable privacy-preserving AI model training.
Synthetic Data Generation methods for health data

The current landscape: Synthetic data generation (SDG) methods use statistical, probabilistic, and deep learning models to replicate real data (RD) distributions. Popular techniques include Bayesian networks, Neural Networks (NNs), and Generative Adversarial Networks (GANs), which are particularly effective for structured clinical data, free text, and sequencing data.
The SYNTHIA approach: We will leverage high-quality data from cohorts, clinical trials, and Real-World Data (RWD) to enhance the accuracy and generalization of state-of-the-art SDG models. Access to multicentre, harmonized datasets across countries enables adaptation to diverse patient populations and healthcare practices. We focus on advancing SDG methods for multimodal and longitudinal data, using automated benchmarking workflows and building on the OpenEBench framework for validation. SDG models will be fine-tuned in a federated environment, ensuring high-quality synthetic data generation from distributed datasets, aligning with the needs of the upcoming European Health Data Space (EHDS).
Synthetic Data evaluation assessment

The current landscape: Evaluating synthetic data (SD) involves assessing its privacy, quality, and utility for its intended use. This ensures that SD is not personal data, adheres to ethical and legal standards, and retains the statistical properties of the original data. Privacy evaluation verifies compliance with data protection standards, while quality and utility assessment ensures SD maintains statistical similarity, predictive accuracy, and minimal bias. Challenges remain in developing standardized validation metrics, particularly when real data (RD) availability is limited, complicating comparative assessments. The lack of consensus on evaluation methods highlights the need for further research in this field.
The SYNTHIA Approach: We will develop a comprehensive framework to evaluate synthetic data (SD) and SDG models in terms of privacy, quality, and utility. This framework will address gaps in current methods by introducing new metrics, enhancing fairness evaluations, and improving privacy standards, including real-time assessment scalability. It will also validate the clinical utility of SD across diverse scenarios, such as data augmentation and synthetic cohorts, to support translational research, accelerate drug development, and advance personalized medicine. We aim to set new standards for robust and comparable SD evaluation in healthcare.
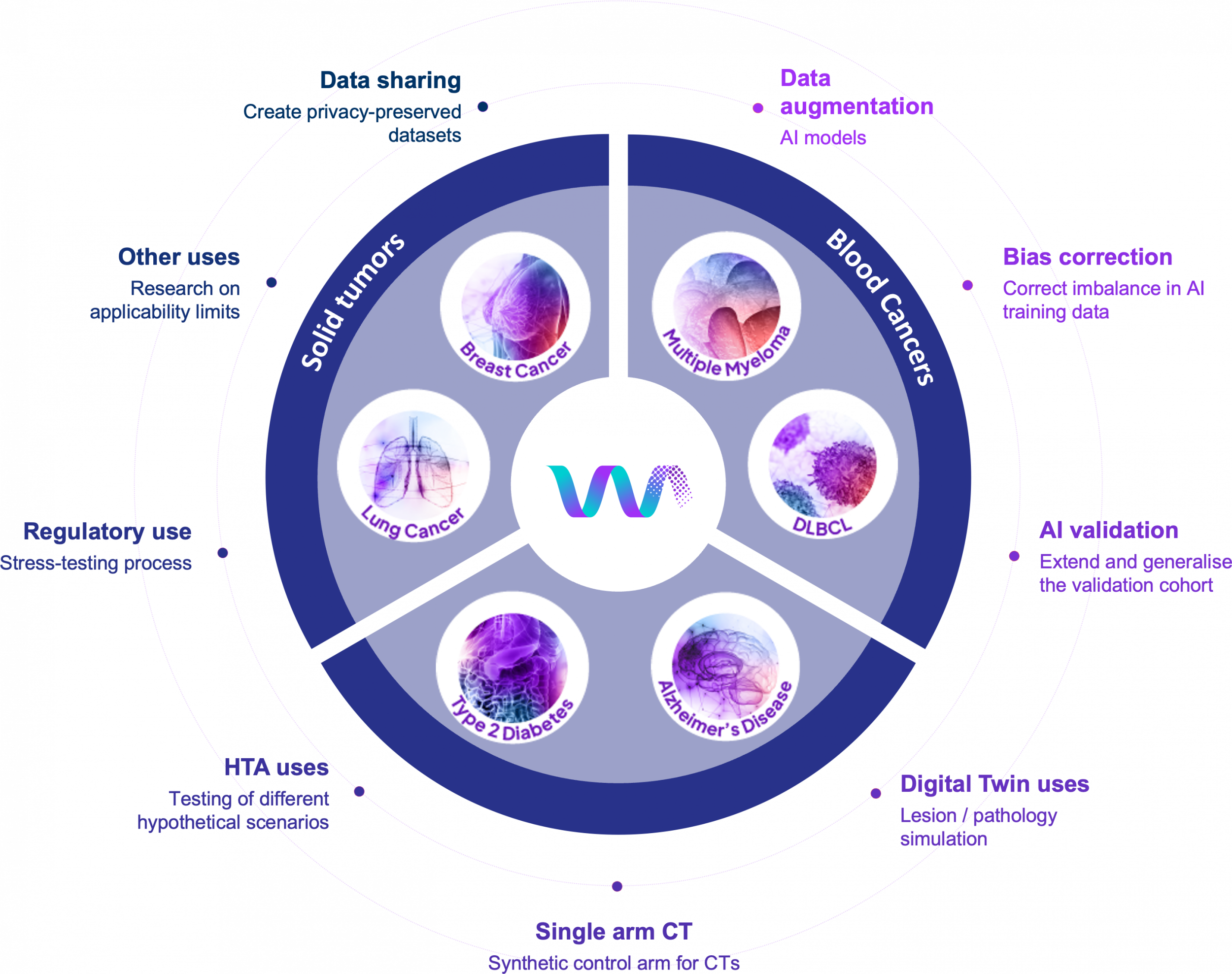
Synthetic Data use in healthcare applications towards personalised medicine

The current landscape: Personalized medicine relies on diverse, multimodal real-world data (RWD), but gathering large, complete datasets is challenging, especially for rare diseases. Real data often have imbalances and missing information. Synthetic data (SD) offers a scalable, privacy-preserving solution, enabling data augmentation, generation of missing information, and creation of synthetic control arms for clinical trials. These advances reduce costs, accelerate research, and support secondary analyses, making SD a vital tool for innovation in personalized medicine.
The SYNTHIA Approach: We will develop advanced generative models integrating diverse patient data - clinical, omics, imaging, and text - for multimodal synthetic data generation (SDG). Using cutting-edge architectures like LLMs and diffusion models, it will enable cross-modal understanding and longitudinal data simulation. In addition, we will validate SD in predictive ML models, Digital Twin simulations, and Clinical Decision Support Systems (CDSS), accelerating health interventions and chronic disease tools. By addressing legal challenges, we will promote secure adoption of SD, advancing impactful data-driven solutions for healthcare.
Empowering AI and Health Research with Synthetic Data
SYNTHIA will provide a comprehensive suite of resources to empower researchers, developers, and healthcare innovators with cutting-edge synthetic data capabilities such as: Access to tools and methods for Synthetic Data Generation (SDG), validated in a set of clinical use cases; Access to predefined, clinical-grade Synthetic Data (SD) collections for a set of clinical use cases; For various data types, including laboratory results, clinical notes, genomics, imaging, and mobile health data; For unimodal, multimodal and longitudinal dataset; With a framework for SD evaluation, ensuring privacy, quality and bias mitigation.
Targeted Synthetic Data Applications
The SYNTHIA targeted SD Applications will be designed to address specific clinical and research needs by delivering purpose-built synthetic datasets and tools tailored to real-world healthcare scenarios.